The latest version of IWFM uses hdf output file format. This makes the reading output files a bit more difficult since the outputs are not in ASCII format but way more efficient. Luckily Matlab, R and many other languages can handle hdf formats quite easily.
Groundwater Zone Budget file
The first step to read any hdf file in matlab is to read the information that is contained in the file
|
1 |
GB_bud_info = h5info(fullfile(c2vsim_path, 'Results','C2VSimFG_GW_ZBudget.hdf')); |
The GB_bud_info is a structure with many fields that contain plenty of useful information. After examining the structure in my version the GB_bud_info contained the field Groups, which has the following structure

If we expand the dataset for the Layer1 we see the following structure
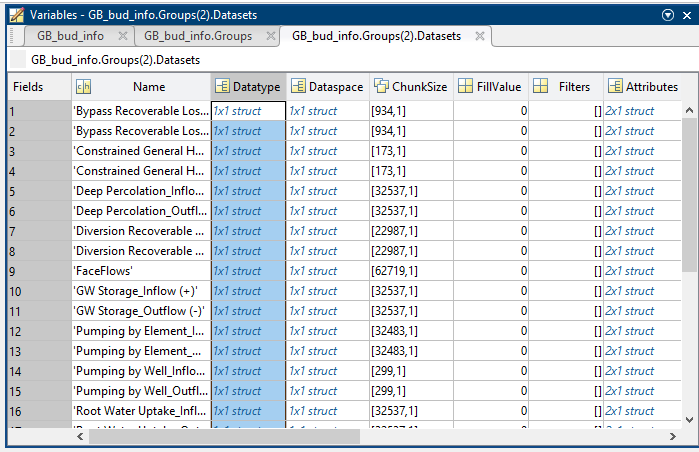
From this table we can find the row where each property is located . To read the data for a specific property we use the following. The Storage for example is the row 22. The following snippet loops through the layers and adds the entire storage from all layers
|
1 2 3 4 5 |
CVstorage = zeros(504, 32537); for ii = 1:4 CVstorage = CVstorage + h5read(GB_bud_info.Filename,... [GB_bud_info.Groups(1+ii).Name GB_bud_info.Name GB_bud_info.Groups(1+ii).Datasets(22).Name])'; end |
The units of the hdf file are in feet. Since this is storage the units are cubic feet. To generate the famous storage depletion plot of Central valley for example after we have calculated the above we can do the following
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
% Create the time variable for the plot start_date = datetime(1973,10,1); tm = start_date + calmonths(0:503); % Calculate the storage from all elements CVcumulativeStorage = sum(CVstorage,2); % convert from feet to acre feet CVcumulativeStorage = CVcumulativeStorage * 2.29569e-5 % Convert to million acrefeet CVcumulativeStorage = CVcumulativeStorage /1000000 % and do the plot plot(tm,CVcumulativeStorage - CVcumulativeStorage(1),'linewidth',2) xlabel('Time') ylabel('Storage depletion [MAF]') grid on |

In the case of storage the data have dimensions as we see in the ChunkSize field 32537 and we can somewhat safely assume that the 1st row correspond to 1st element etc. However the ChunkSize for the Streams (rows 23,24) is 9885.
|
1 2 |
StreamBud=h5read(GB_bud_info.Filename,... [GB_bud_info.Groups(2).Name GB_bud_info.Name GB_bud_info.Groups(2).Datasets(23).Name])'; |
The size of the StreamBud variable is 504×9885. Therefore from this matrix we cannot tell which element corresponds to the values. This information exists under Group(1).Datasets
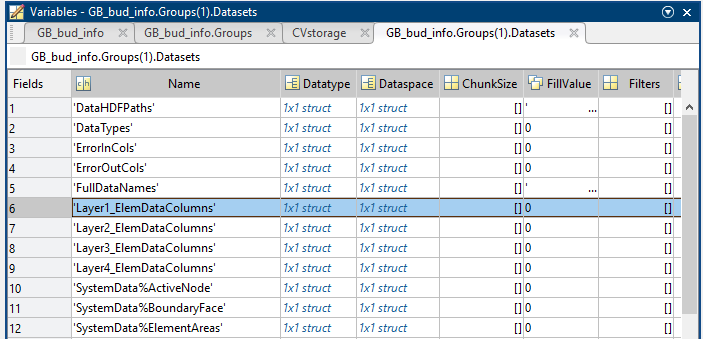
The 6th row contains the correspondence between data and elements. To read it use
|
1 |
ids = h5read(GB_bud_info.Filename,[GB_bud_info.Groups(1).Name GB_bud_info.Name GB_bud_info.Groups(1).Datasets(6).Name])'; |
which returns a matrix 24×32537 (note that the above code transpose the output). Obviously the columns are related to the elements but how about the rows? This information exists in the 5th row of the above variable which we can read it as
|
1 |
Colnames = h5read(GB_bud_info.Filename,[GB_bud_info.Groups(1).Name GB_bud_info.Name GB_bud_info.Groups(1).Datasets(5).Name]); |
The Colnames variable consist of 24 rows! The 3rd row is the Streams_Inflow (+). The elements that are associated with the stream budget are the nonzero ones in the 3rd row of the ids matrix which can be extracted easily
|
1 |
stream_elem_ids = find(ids(3,:) ~=0); |
Extract Budget terms for a sub-region
In the following we are going to extract the groundwater pumping for the 21st subregion. Note that this is not a continuation of the above
First we read the mesh information where the correspondence between subregions and mesh element is defined. For the following I’m using the latest version of the modeling which can be cloned from this repo. I also use one custom matlab function to read the element file which can be found in here
|
1 2 3 |
c2vsim_path = fullfile('..','C2VsimV1','c2vsim-working'); GB_bud_info = h5info(fullfile(c2vsim_path, 'Results','C2VSimFG_GW_ZBudget.hdf')); c2vsim_mesh = readIWFM_Elements(fullfile(c2vsim_path,'Preprocessor',"C2VSimFG_Elements.dat"), 32537, 142); |
The pumping is not printed for all elements and not all layers pump from the same elements. The following is looping through the 4 layers of the models and extract which elements are associated with the budget terms. We also read the column names
|
1 2 3 4 |
Colnames = h5read(GB_bud_info.Filename,[GB_bud_info.Groups(1).Name GB_bud_info.Name GB_bud_info.Groups(1).Datasets(5).Name]); for ii = 1:4 ids{ii,1} = h5read(GB_bud_info.Filename,[GB_bud_info.Groups(1).Name GB_bud_info.Name GB_bud_info.Groups(1).Datasets(5+ii).Name])'; end |
In this version the column names consists of 26 rows and the rows 21-24 are related to pumping. However we are interested only in the negative terms which denote extraction from the groundwater. Besides the positive pumping is zero in the model. The rows 22 and 24 correspond to element and well pumping.
Before assembling the budget terms we can find the elements of the subregion of interest. Here I’ll use the 21st subregion
|
1 2 |
isub = 21; subreg_elem = find(c2vsim_mesh(:,end) == isub); |
The next snippet loops through the layers and extracts the element ids for the element and well pumping. If any element has no pumping then the id will be 0 so we remove the 0 entries. Last we read the data from the hdf5 file and sum the pumping from all the elements for each time step and save the results to a matrix.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
elem_pump = zeros(504, 4); well_pump = zeros(504, 4); for ii = 1:4 elem_pump_ind = ids{ii,1}(22,subreg_elem); well_pump_ind = ids{ii,1}(24,subreg_elem); elem_pump_ind(:,elem_pump_ind==0) = []; well_pump_ind(:,well_pump_ind==0) = []; tmp_elem_pmp = h5read(GB_bud_info.Filename, [GB_bud_info.Groups(1+ii).Name GB_bud_info.Name GB_bud_info.Groups(1+ii).Datasets(13).Name])'; elem_pump(:,ii) = sum(tmp_elem_pmp(:,elem_pump_ind),2); tmp_well_pmp = h5read(GB_bud_info.Filename, [GB_bud_info.Groups(1+ii).Name GB_bud_info.Name GB_bud_info.Groups(1+ii).Datasets(15).Name])'; well_pump(:,ii) = sum(tmp_well_pmp(:,well_pump_ind),2); end |
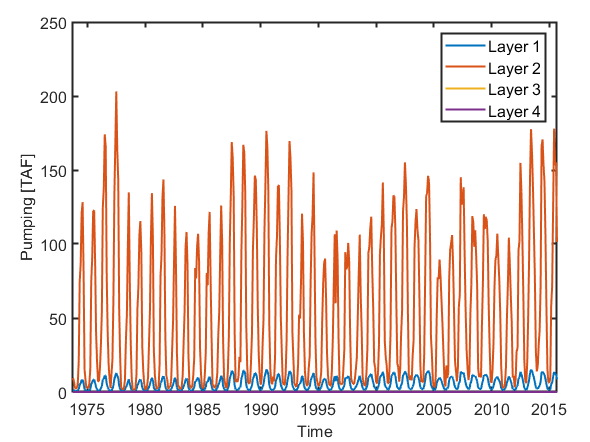
Now let’ s plot the pumping for each layer separately
|
1 2 3 4 5 6 |
start_date = datetime(1973,10,1); tm = start_date + calmonths(0:503); plot(tm, elem_pump * 2.29569e-5/1000) xlabel('Time') ylabel('Pumping [TAF]') legend('Layer 1','Layer 2','Layer 3','Layer 4') |